Public Notes: Running Python in Azure Batch on Windows using the Azure Portal
Posted by sseely in Uncategorized on July 19, 2018
TLDR; This post explains how to setup an Azure Batch node which uses Windows using installers. It also explains how to use application packages to preload Azure Batch nodes with utilities so that tasks can just be command lines. The explanation use case is “run a Python script”, but should apply more broadly to “install tools, distribute stuff, and run command lines.”
PDF Version of this article (which has a bit better formatting)
When I start experimenting with something, I do not start out with writing code to automate everything. Sometimes, I try to use a GUI to bootstrap my process, then automate when setup is correct. Why? A lot of environments, like Azure, will allow for fast cycles from the UI tools. My latest adventure took a bit of time, so I’m documenting what I did.
Here’s the context: I am developing a mid-sized example project for scalability. If everything goes to plan, the demo will show how to solve the same problem with Azure Batch and the Azure Kubernetes Service. The demo is targeting a special kind of data scientist: an actuary. Actuaries frequently write code in one of three languages: APL, Python, and R. I’m focusing on Python.
My goals:
- Configure everything through the Azure portal.
- Install Python on the batch node at startup.
- Use the application packages feature to deliver the Python virtual environment prior to any tasks running.
- Run a command line without resources to make sure I can run a script in the Python virtual environment.
What follows is essentially a lab for you to follow and do the same things I did. As time marches forward, this lab’s correctness will degrade. Hit me up on LinkedIn if you catch this and I may go back and update the details.
For all the Azure pieces, try to keep things in the same region. I’ll be using East US. This isn’t necessary, but is helpful for the parts that transfer files. Staying in the same region gives better speed.
1 Create a new project in PyCharm
- Open up your editor; I’m using PyCharm. Details for other editors will differ. Set the location to wherever you like. I’m naming the project BatchDemo.
- Setup a New environment using Virtualenv. The location will be in the venv directory of your project. For the base interpreter, use the one installed on your machine already.
For me, the dialog looks like this:

- Click on Create.
- Add a new file, addrow.py, to the project in the BatchDemo directory.
- Add the library to use table storage.
- Select File–>Settings–>Project: BatchDemo–>Project Interpreter.
- In the list of packages, you’ll see a plus sign ‘+’. Click on that.
- Select azure-cosmosdb-table. Click on Install Package.
- Close the Available Packages window once done. My machine looked like this before I closed the window:

- Click OK on the Settings Window. You should now have a number of packages installed.
- Add the following code to the addrow.py file. The code is fairly “Hello, world!”-ish: add a row to a Table Storage table (using libraries from the azure.cosmosdb namespace, but interacts with Storage, so no, not intuitive). The script is simple and adds one row to a table named tasktable:
from azure.cosmosdb.table.tableservice import TableService import datetime def main(): table_name = 'tasktable' table_service = TableService( account_name="<your Azure Storage Account Name>", account_key="<your Azure Storage Account Key>") if not (table_service.exists(table_name)): table_service.create_table(table_name) task = \ { 'PartitionKey': 'tasks', 'RowKey': str(datetime.datetime.utcnow()), 'description': 'Do some task' } table_service.insert_entity(table_name, task) if __name__ == "__main__": main()
For the highlighted code, take the name of one of your Azure Storage Accounts and a corresponding key, then plug in the proper values. If you need to create a storage account, instructions are here. To get the keys, look in the same doc (or click here) and follow the instructions. If you create a new storage account, use a new resource group and name the resource group BatchPython. We’ll use that group name later too.
One last comment here: for a production app, you really should use Key Vault. The credentials are being handled this way to keep the concept count reasonably low.
Test the code by running it. You should be able to look at a table named tasktable in your storage account and see the new row. The RowKey is the current timestamp, so in our case it should provide for a unique enough key.
Once you have all this working and tested, let’s look at how to run this simple thing in Azure Batch. Again, this is for learning how to do some simple stuff via a Hello, World.
2 Create a batch account
In this step, we are going to create a batch account which I’ll refer to as batch_account in here; your name will be different. Just know to substitute a proper string where needed.
- In the Azure portal, click on Create a resource.
- Search for Batch Service. Click on Batch Service, published by Microsoft.
- Click on Create.
- Account name: For the account name, enter in batch_account [remember, this is a string you need to make up, then reuse. You’re picking something unique. I used scseelybatch]
- Resource Group: Select BatchPython. If you didn’t create this earlier, select Create New.
- Select a storage account to use with batch. You can use the same one you created to test the table insertion.
- Leave the other defaults as is.
- Click on Create.
3 Upload the Python Installer
Upload the Python installer which you want to use. I used the Windows x86-64 executable installer from here.
- In your storage account, create a container named installers.
- In the Azure Portal, navigate to your Storage Account.
- Select Blob ServiceàBrowse Blobs
- Click on + Container.
- Set the Name to installers.
- Click on OK.
- Once created, click on the installers container.
- Upload the Python installer from your machine.
- Click on Upload.
- In the Upload blob screen, point to your installer and click on Upload.
- Wait until the upload completes.
- Get a SAS URL for the installer.
- Right click on the uploaded file.
- Select Generate SAS.
- Set the expiration of the token to some time in the future. I went for 2 years in the future.
- Click on Generate blob SAS token and URL

Copy the Blob SAS URL. Store that in a scratch area. You’ll need it in a bit.
4 Create a Batch Application
- Going back to your machine, go to the BatchDemo directory which contains your addrow.py file along with the virtual environment. Zip up BatchDemo and everything else inside into a file called BatchDemo.zip. [Mine is about 12MB in size]
- Open up your list of Resource Groups in the portal. Click on BatchPython.
- Click on your Batch account.
- Select FeaturesàApplications
- Click on Add.
- Application id: BatchPython
- Version: 1.0
- Application package: Select BatchPython.zip
- Click on OK.
The file will upload. When complete, you’ll have 1/20 applications installed.
- Click on BatchPython.
- Set Default Version to 1.0.
- Click on Save.
5 Create a Batch Pool
- Open up your list of Resource Groups in the portal. Click on BatchPython.
- Click on your Batch account.
- Select on FeaturesàPools
- Click on Add.
- Pool ID: Python
- Publisher: MicrosoftWindowsServer
- Offer: WindowsServer
- Sku: 2016-Datacenter
- Node pricing tier: Standard D11_v2 [Editorial: When experimenting, I prefer to pick nodes with at least 2 cores. 1 for the OS to do its thing, 1 for my code. I’ll do one core for simple production stuff once I have things working. This is particularly important to allow for effective remote desktop/SSH. The extra core keeps the connection happy.]
- Target dedicated nodes: 1
- Start Task/Start task: Enabled
- Start Task/Command Line: We want this installed for all users, available on the Path environment variable, and we do not want a UI.
python-3.6.6-amd64.exe /quiet InstallAllUsers=1 PrependPath=1 Include_test=0
- Start Task/User identity: Task autouser, Admin
- Start Task/Wait for success: True
- Start Task/Resource files:
- Blob Source: Same as the URL you saved from the piece labeled “Upload the Python Installer”. The SAS token is necessary.
- File Path: python-3.6.6-amd64.exe
- Click on Select
- Optional Settings/Application packages
- Click on Application Packages.
- Application: BatchPython
- Version: Use default version
- Click on Select
- Click on OK.
The pool will be created. In my experience, creating the pool and getting the node ready can take a few minutes. Wait until the node appears as Idle before continuing.

6 Run a job
- Open up your list of Resource Groups in the portal. Click on BatchPython.
- Click on your Batch account.
- Select on FeaturesàJobs
- Click on Add
- Job ID: AddARow
- Pool: Python
- Job manager, preparation, and release tasks:
- Mode: Custom
- Job Manager Task:
- Task ID: AddARowTask
- Command line:
cmd /c %AZ_BATCH_APP_PACKAGE_BATCHPYTHON%\BatchDemo\venv\Scripts\python.exe %AZ_BATCH_APP_PACKAGE_BATCHPYTHON%\BatchDemo\addrow.py
Note on the environment variable: Application packages are zip files. Batch puts the location of the unzipped application package into an environment variables in one of two ways, depending on if you select the default version or a specific version.
Default: AZ_BATCH_APP_PACKAGE_
Versioned: AZ_BATCH_APP_PACKAGE_
- Click on Select
- Click on OK
The job should start running immediately. Because it’s a short task, it’ll finish quickly too. Click on Refresh and you’ll probably see that the AddARowTask has completed.

You can then verify the output by opening up the table and looking at the rows. A new one should be present. I’ll expect a row that completed near 21:33 on July 19; the time will be recorded as UTC, and I’m in Redmond, WA, USA, which is 7 hours behind UTC time.

That view is courtesy of the Azure tools present in Visual Studio 2017.
7 So, what next?
Now that you’ve done all this, what does it mean? For your batch pools, you could preload them with a common toolset. The resource files you pass in to a job can be files to operate on, independent of binaries. Your tasks start times can be greatly reduced by loading the prerequisites early. Could you do this with custom VMs? Sure, but then you need to keep the VMs patched. This mechanism allows you to use a patched VM and just install your few items.
This is definitely a toy example, meant to show how to do the initial setup in the portal. Here’s what you want to do for automation purposes:
- Script all of this.
- For the Python piece, add a mechanism to create the zip file after you have a successful build and test.
- Script the management of the binaries, creating the Batch Service, and configuring the pools and application package(s).
- Add an integration test to validate that the pool is ready to run.
- Minimize the number of secrets in the code to 0 secrets. Use Key Vault to manage that stuff.
Thoughts on Day 3 of Money 2020, Europe
Posted by sseely in Uncategorized on June 6, 2018
Walking the show floor at Money 2020, one sees lots of payment providers. Its no shock then that today, I saw a lot of talks on how this works. This is in keeping with the theme of the show: the future of money. The previous two days, I did hear a fair amount of talk about moving away from paper money, what to do about fiat currency vs. other currency, and difficulty in managing payments. Today, we heard about what is possible with payments.
The facts keep stacking up around us about people preferring to pay electronically instead of with plastic or currency. Those electronic payments are happening in apps:
The first three are as phone OS capabilities, the last two are via apps on the phones. Electronic payments make a number of things better for consumers, retailers, and credit institutions (banks, credit card companies, etc.). For consumers, they get convenience. For retailers, they find less friction at checkout. For credit institutions, they get reduced fraud. So far, so good, right? Well, what I learned after this was a lot more interesting: if you are just reducing payment friction, you are leaving a lot of opportunity on the table. Opportunity for:
- Learning about the customer. You are collecting their buying habits. Imagine what you could do if you did more to help, what else could you learn?
- Getting retailers to use your payment system. You know a lot about your customers and what they like to buy. You can now refer them to other retailers, services, and so on. Use that to convince retailers that if they use your system, you will drive more interested customers their way.
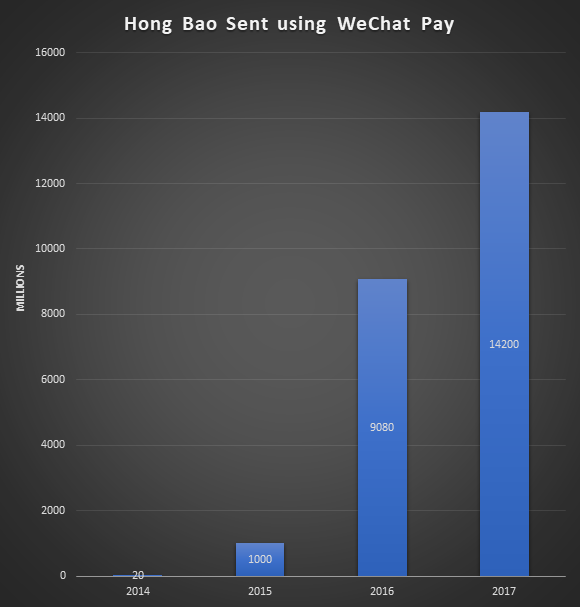
- Delight your customers in novel ways. WeChat has delighted their Chinese users by making it easier to send Hong Bao (a monetary gift in a red envelope) to others. Their users love this feature. Here’s what the growth has looked like year over year (numbers are from a presentation by Ashley Guo of WeChat):
You can also look at Ant Financial/Alipay. Despite their name, they are not a payment company; they are a marketing company. You use them to schedule doctor appointments, figure out how to travel on public transportation or taxi, manage vacations, discover information about products, and so on. And yes, when the service is performed or goods are purchased, they also make sure that the vendor is compensated by you. But, they make it all seamless. The product has been successful in China, turning their tier 1 and tier 2 cities into cashless areas. The services are so popular with their Chinese user base that the apps are used around the world at high end retailers down to businesses like Burger King.
Both WeChat and Alipay emphasized that they use the data to better market to users. The users like the targeting in their lives. When traveling, they discover attractions and restaurants that appeal to them because the app knows them so well. The businesses are happy to participate because they acquire customers who may not have found them otherwise.
What I saw today was a lot of companies thinking about how to make transactions easier by working with banks and credit card companies to remove plastic from your life. This is great. I look forward to the day when my wallet no longer bulges because of all the cards I need to carry.
I also saw something wonderful and scary: a world where things will generally improve for me if I let artificial intelligence and machine learning see all the things I do. By knowing what I eat, where I go, and so on maybe the algorithms can warn me to start doing some things (walk more) and stop doing other things (keep it to two coffees a day). Scary, because I worry what would happen if all that data was combined in some nefarious way. For example, if the algorithm senses that I get out of depression by spending money, maybe the algorithm seizes on this by getting my spending up using knowledge sales people only wish they knew. Or, me being denied a job because the data leaks that I buy [something the employer wants to look out for: alcohol, cigarettes, etc.].
In all, a very interesting day around payments.
Thoughts on Day 2 of Money 2020, Europe
Posted by sseely in Uncategorized on June 5, 2018
The conference at Money2020 has many tracks. Given the amount of questions I have seen from customers around distributed ledger technology (DLT) (Blockchain, Hyperledger Fabric, Ethereum, Corda, etc.), I attended that track. In the track, there were a fair number of panels staffed by either users of DLT, consortiums looking to make their use cases more ubiquitous, and implementers of DLT. While all groups had different lenses on what is going on, they tended to agree on what problems DLT solves and how to use the technology.
For finance, DLT helps eliminate a lot of verification/validation work with happens in the middle and back office.
This has been framed as the “Do you see what I see?” (DYSWIS diss-wiss) problem. DYSWIS solution attempts from the past have involved things like cryptographic signatures where two parties compare signatures of the data. Those solutions fail for the main reason crypto comparison always fails: normalization of data prior to signing. DLT solutions solve this in different ways, but they all have ways to sign facts and achieve consensus about the facts.
Anyhow, back to the main point about saving time confirming that what I see matches what you see. The finance industry has used a strong central authority for smaller, contract-less transactions in the form of Visa, Mastercard, and others. Then, we get to more complex transactions. How complex? Consider this scenario:
A European importer purchases some goods from an East African exporter. The importer prefers to pay when goods arrive. The exporter prefers to be paid when goods are shipped. Neither gets their preferred mode because of risk. The bank for the importer needs to issue a letter of credit. The exporter also insures the goods until delivery. The shipper, sitting between importer and exporter, will orchestrate the movement of the goods through several partners, who in turn may use other partners. Finally, the exporter will insure the goods in case of loss. It is normal for the shipment to pass through around 30 entities and have around 200 transactions [info from a presentation by TradeIX.com].
How does DLT help here? Using DLT, the importer, exporter, bank, shipper, and insurers can all see what is happening in real time (within minutes). Because facts are attested to and sent digitally, human transcription errors disappear. This means that humans may only to verify that the numbers and such look “right” before allowing their end of a transaction to proceed. This frees up human capital to do more valuable tasks.
So, one question you might ask yourself is “which DLT is right for me?” More than a few of the C-level folks on panels said a variant of “I don’t care. I just want something that works.” For those of you that care about the details and optimal choices, understand this: if you are joining a DLT consortium and it doesn’t use what you consider to be best, you need to just build something that works with the choice. If you complicate things by creating translation layers between something like Corda and Ethereum, expect to be looking for a new job tomorrow (because you’ve been fired).
The great news here is that the businesses now understand how to apply DLT. They have found that their normal transaction volumes of 200 TPS are already handled by most enterprise DLT solutions. They also understand the difference between on-chain and off-chain data, so don’t put PII and other GDPR prohibited data on the chain.
Over and over again, I heard the C-level folks say “I want DLT for the use cases where I spend a lot of time verifying that data was input correctly because that work costs too much time and slows down the business.” Then, using those facts, they want to drive cost savings elsewhere. The instant verification of the truth reduces financial risk. The reduced financial risk means the business can now make decisions sooner to further improve their ability to move money, settle accounts, and so on.
In 2018 you will hear a number of implementations of DLT in a number of markets. At this time, it seems prudent to be familiar with the leading contenders in the space. At the moment, these seem to be (in no particular order):
This will be an exciting year for DLT.
Thoughts on Day 1 of Money2020, Europe
Posted by sseely in Uncategorized on June 4, 2018
I just finished day 1 of Money 20/20 Europe. I stuck mainly to the large sessions and to the show floor. What I saw was a repeated vision of what this group in finance sees as the next set of important things to be tackled. Everything they are doing revolves around the customer and making things better for customers. Depending on where you are in the financial ecosystem determines which pieces you are building and which pieces you are integrating.
From the banking side, we heard from many folks. I took the most notes from the talks by Ralph Hamers (CEO of ING Group) and Andy Maguire (Group COO at HSBC). After these two, the themes repeated which only solidified that they weren’t unique in their visions. Because banks already have the balance sheets and other nuts and bolts of building a banking business, their vision is to provide a banking platform that other businesses can plug into. Any workable platform must be open: competitors need to be able to plug into it just as easily as partners. This will allow the bank to stay good at what it knows while letting other partners fill the gaps with the wide variety of expertise that the bank does not have so that it can participate in new opportunities more easily. For example, many banks are finding success by going into geographies where their customers only interact with them over a digital experience: no human to human interaction over 99% of the time. To do this, they craft their platform and their onboarding experience to be as easy to use as possible. Several banks talked of doing work to reduce the integration times with their platforms from months down to weeks. These efforts are paying off to allow the banks to find ways to interact with more customers in more countries.
From the FinTech side of the house (which for this conference so far is the “everyone else” even though I know this leaves out personal finance folks), I saw a lot of interesting technology. A lot of the technology focused on a few areas, all with interesting takes on how to accomplish the goals. I saw a lot of distributed ledger technology (aka blockchain) with implementations that have already gone live. It wasn’t clear to me how blockchain is being leveraged, but tomorrow promises to have a number of talks around the “what” and “how”. The show also has a number of folks presenting different ways to present your identity. Many of these still focus around the two factors for authenticating and many are avoiding passwords, PIN codes, and the like. The primary mechanism here is:
- Some biometric. Two most commonly cited are fingerprint and face.
- Smart phone.
So, yes, the argument that goes “What about people from [some part of world that they think doesn’t have Android or Apple phones]?” is not under consideration. In the countries where the banks operate, they know that most of their customers have smart phones.
The final thing I noticed is that AI came up a bunch and it was all nebulous to the speakers. Asking some of the AI firms on the floor, the sales folks know that they have data scientists and those people build and maintain their models. AI/ML is being applied to Know Your Customer/Anti-money Laundering work as well as fraud detection. Given the sales process, my guess here is that the people who need the tech will talk to those who make it and then have their engineers have the nitty gritty discussions of integration. I’m definitely looking forward to learning more there.
I also spent a bit of time on the show floor. Because it’s banking, a lot of the vendors create solutions that run in the client data center OR the cloud. For those folks, I’d like to let you know that you should look at joining the Azure Marketplace. This can give you ease of deployment for your customers who run in Azure and is fairly handy for VM only deployments. Contact me and I can help you get on board.
Copying files from a Docker container onto local machine
Posted by sseely in Uncategorized on December 29, 2017
This past week, I’ve spent time wiping away my ignorance of containers. To do this, I started in my usual way:
- Buy a bunch of books. Probably too many.
- Work through books, doing exercises as I go.
The first book I’m running through is Using Docker: Developing and Deploying Software with Containers by Adrian Mouat. I’m posting this bit now to hopefully help others.
When working through the exercise to backup the redis database in Chapter 3, I ran the command to backup the database:
docker run --rm --volumes-from myredis -v $PWD/backup:/backup debian cp /data/dump.rdb /backup/
This then emits the error message:
C:\Program Files\Docker\Docker\Resources\bin\docker.exe: Error response from daemon: Drive has not been shared. See 'C:\Program Files\Docker\Docker\Resources\bin\docker.exe run --help'.
This is happening because I never shared the C-Drive with Docker. To do this, right click on the Docker icon sitting in your toolbar and select Settings… . Then, select Shared Drives and check the drive(s) on your system which you want to be able to use. 
Upon clicking Apply, enter your credentials. The command should now work.
One other note: I found that the command did not work right in cmd.exe or some bash shells. It did work just fine from a powershell window. So, that’s another note…
.NET Fx version to Azure Cloud Service Mapping
Posted by sseely in Uncategorized on July 7, 2017
Posting this here mostly for me so I can find this easily again:
https://docs.microsoft.com/en-us/azure/cloud-services/cloud-services-guestos-update-matrix.
I’m monitoring this URL, waiting for .NET 4.7 support to appear. I’m hopeful that we’ll see something early in 2017 Q4, but I won’t be holding my breath either 😉
Azure OS Family 5 changes to RDP/Remote Desktop prevent logins on short passwords
Posted by sseely in Uncategorized on January 22, 2017
TLDR; Azure OS Family 5 requires Remote Desktop passwords >= 10 characters. Anything less will cause your login to fail, repeatedly requesting that you re-enter your password.
I ran into an issue when upgrading an Azure application from OS Family 4 to OS Family 5. We have configured RDP for our development deployments. As part of that deployment, we had configured special passwords for each environment. Those passwords had a strong enough length when we added them a few years ago: 8 and 9 characters. OS Family 5 (Windows Server 2016) requires that the passwords are at least 10 characters long.
As a result, we found that the deployment went fine (no errors reported) but that we simply couldn’t log in post upgrade. Looking on the portal, we noted that one has to have a password of at least 10 characters to add Remote Desktop from the portal. We counted the characters in our passwords, adjusted lengths, and found we could login again.
(Re)claiming My Blue Badge
Posted by Scott Seely in Uncategorized on February 1, 2013
TL;DR: Microsoft offered me a position on the Windows Azure Service Bus team and I took it. I’m ex-Microsoft and I reclaim my blue badge on February 11, 2013.
Longer version: From 2000 to 2006, I worked at Microsoft on MSDN and later on Indigo (WCF). The family loved living in Washington state and I loved my job at Microsoft. However, my wife and I don’t ever want to look at life and see ourselves doing things that we know we will regret. One of the things we were starting to regret was not letting our kids get to know their extended family. In 2006, my wife and I chose to return to the Midwest so that our three children (then 10, 5, and 3 years old) could get to know their cousins, aunts, uncles, and grandparents. Since 2006, we’ve been able to attend graduations, weddings, and generally get to visit family whenever the spirit moved us. We got to know everyone in our extended family quite well. As happens quickly, the families have seen their kids get older, other activities occupy more of their time, and this has limited the ease in all of us getting together. Essentially, Thanksgiving works great- everything else is a crap shoot.
Over the last 2 years, getting together just got tougher, so my family reevaluated our goals and wants. We decided we wanted to go back to the Pacific Northwest and I figured that, if I’m going to move there, why not work for Microsoft again? One of the teams I was interested in was the Windows Azure Service Bus team. They had an opening and after a nice, long day of interviews, they decided to take a risk on an RD and Integration MVP. I really clicked with the team, so I accepted the offer. This choice also allows me to work on one of the largest scale systems in the world on a product that ships on an Internet cadence. I’m extremely excited about this opportunity and can’t wait to get into the code.
I plan to continue recording courses for Pluralsight on the weekends and evenings- the authoring/teaching bug bit me back in 1998. Pluralsight provides a great way to scratch that itch.
New work machine
Posted by Scott Seely in Uncategorized on January 28, 2013
Back in 1999, I officially gave up on the desktop computer. Since then, my personal machine has always been a desktop replacement quality laptop. I enjoy being able to take a powerful box wherever I go. This past December, I felt a need to get a portable machine that supported Windows 8 with multi-touch. I’m floored by how light a desktop replacement can be! I wound up with a Lenovo X230 tablet. The thing is small- 12.5” screen. I equipped it with a slice battery so that I can work a full day away from a power source. You can also easily enhance the box to make it a wonderful workhorse. I picked up the I5 configuration with the basic memory and HDD. About 2 hours after receiving the unit from Lenovo, the machine had:
- 16GB RAM (Crucial)
- 256GB mSATA SSD boot disk (Crucial)
- 512GB Samsung SSD
- Screen protector
- Windows 8
When in its docking station, the machine drives a 27” Planar touch screen over DisplayPort and a second regular 27” Acer monitor over a USB to DVI display adapter. For the past several weeks, I’ve been using this setup to get stuff done wherever I go. I’m impressed with how small and light the X230 is. Travelling with this little machine has been pleasant. It’s easy to get work done with it on a plane, including writing code. This machine also runs virtual machines like a champ, which has been helpful for me to get my experimentation done and in just learning new stuff.
I will acknowledge that this laptop is not for everyone. For me, it met some important requirements:
- Support multiple HDDs: I frequently rebuild my system due to the amount of beta software I tend to run. Keeping apps on one disk, data on another means I just need to reinstall my apps—the data is automatically available.
- Support a lot of memory: I use VMs a lot. 16 GB seems to be a good min bar for support, though I would have preferred 32 GB as is supported on the W520.
- Weighs little: I wanted something that was light. I’m getting older and the W520 kills my back when I carry it in a backpack. The x230 is just tiny—and the power supply is super small too!
- Airplane friendly: I like to write code on planes. The W520 wasn’t comfortable to use in coach. The X230 is alright in those small seats.
- Docking station: I don’t want to think about reconnecting monitors, USB, keyboard, mouse, microphone, and more when I want to sit at a desk with bigger screens to get “big things” done. Most of the light and portable machines don’t support docking stations. The X230 does.
Given what is coming out for ultralight laptops over the next 6 months, the X230 still looks like a great option. If you are doing Win8 development and need a touch device, or just want a nice, light development machine, I highly recommend this little beauty.
MVP Program Guest Post: Connected Apps Made Wicked Easy with Windows Azure Mobile Services
Posted by Scott Seely in Azure, C#, Windows 8, Windows Azure Mobile Services on December 3, 2012
A little while ago, I was asked to write a post on some topic for the MVP Program blog. I suggested a post on Windows Azure Mobile Services titled Connected Apps Made Wicked Easy with Windows Azure Mobile Services. That post is up now. So excited!!!

You must be logged in to post a comment.